


活动回顾
10月31日,第二期Docker&Kubernetes技术沙龙在宇宙中心五道口如期举行。这期沙龙的主题是集群管理。四位讲师分别从集群资源调度、网络高可用、集群监控和产品四个角度分享了他们在集群方面积累的知识和经验。参加沙龙的技术人员,热情很高,踊跃讨论,现场气氛十分活跃。
1. Kubernetes中的资源管理(调度器设计和资源QoS) –丁海洋(华为)
丁海洋的分享大致分为三部分:k8s简介,k8s资源管理机制,k8s现存问题。
Kubernetes(K8s)是Google出品的容器集群管理工具,目前已经在GitHub上开源(https://github.com/kubernetes/kubernetes )。借助于强大的社区,k8s自从发布热度就一直上升,版本迭代周期也比较短,目前已经发布稳定版1.0。k8s的主要概念有Container、Pod、Service、Replication Controller、Label&Selector(见下图),具体特性和原理大家自行参考官方文档(http://kubernetes.io/v1.0/ )。K8s采用了微服务模式,Master节点上运行组件kube-apiserver、kube-scheduler、kube-controller-manager和etcd,slave节点上运行组件 kubelet、kube-proxy和flannel。组件之间松耦合,一些组件可以被替换。
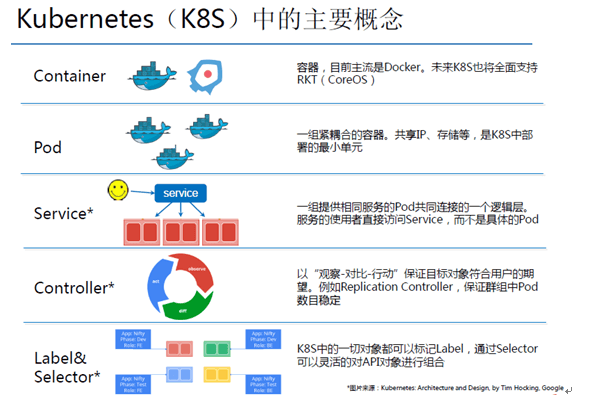
K8s管理资源的策略实现考虑到集群中的单个应用和整个集群两个层面。从应用的层面来看,“为每个Pod寻找合适的部署节点,保证用户体验”,k8s这块做得比较完善,设计了调度器,资源QoS和Auto-Scaling策略,也是丁海洋讲师重点分享的内容;从集群层面来看,“提高资源利用率,控制租户的资源配额”,k8s为此设计了资源超售、多租户资源配额管理、资源再平衡和实时监控,但目前的实现并不是很理想,实时监控更是处于缺省状态。关于调度器的架构设计和细节、资源QoS的定义和策略,这里不多赘述。
K8s调度器存在一些不足,比如目前不支持多个调度器,单个调度器也支持一个规则等,未来这都是优化的方向。另外资源QoS也只是在开发中,很多定义还不是很清晰。K8s才刚刚发布v1,未来还有很长的路要走。谈及华为对K8s的贡献,丁海洋讲师颇为自豪:目前华为主导了一些k8s特性的开发,commit数量也排前五。
问答精选:
a. 如何看待Docker Swarm和K8s,k8s二次开发比较麻烦,有没有在生产环境下使用的公司?
答:Docker Swarm倾向于把集群看成一个大机器,而k8s把集群当成可调度的资源。目前已经有一些公司在生产环境使用k8s。
b. 关于pod,一个pod内运行多个container,container是否同质?
答:Pod内运行的多个container理论上应该功能各不相同,实现互补,没必要同质。使用同质的Pod比较合理。
c. 关于pod,一个pod内的多个container是否会分布在多个node上?
答:Pod是最小的调度单元,一个pod的多个container分布在同一个node上。
d. 关于pod,如何定义一个pod的资源需求,网络是怎么处理的?
答:Pod的资源需求就是pod内所有container资源需求的总和,只是单纯的叠加。目前v1中并没有对网络进行处理,将来v1.2会有。
e. 关于资源QoS,request和limit,内存超额后,pod会被杀死,而cpu超额却不会,设计如此还是cpu超额尚未开发?
答:资源分两种:可压缩和不可压缩的。内存是不可压缩的,所以内存超额后会杀死容器。而cpu是可压缩的,即使超额也不会造成死机,所以CPU还没有做,不过后面会做。
f. Pod作为基本调度单元,container的监控是如何做的? 答:K8s提供了pod级别和container级别的监控
g. 目前k8s master能够管理子节点的最大个数?
答:目前在性能尚可的前提下,支持最多1K个节点,每个节点默认40个Pod。
2. Etcd高可用实践 — 王鹏(光音网络)
Etcd是一个高可用的分布式键值存储数据库,k8s集群采用etcd存储集群的网络拓扑信息。Etcd提供了一套restapi,因此可以使用任意一种编程语言对其进行Get/Set/Recursive/Directory等操作。Etcd包含Storage、Raft、Entry和Snapshot四个模块(如下图),其中Raft一致性算法是保证etcd高可用和数据一致性的关键。王鹏讲师分享了Raft算法的原理。Raft主要实现两个功能:Leader Election和Log Replication。Leader Election的规则是:在一个Etcd集群中,只有超过半数node投票通过,才能成为Leader节点。Log Replication是指将数据写入etcd集群时,数据的同步机制。具体过程可以参考动画http://thesecretlivesofdata.com/raft/#home 。
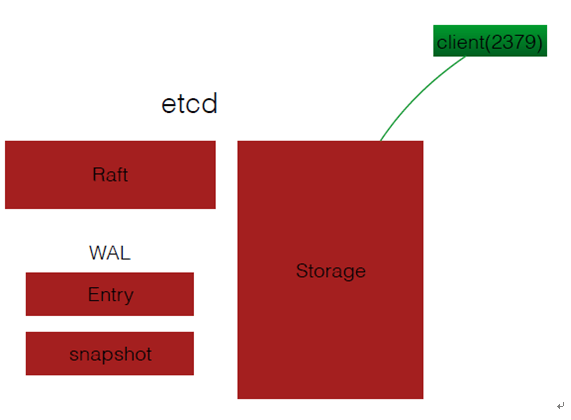
之后,王鹏讲师分享了光音网络使用etcd方面的一些经验。首先是etcd的集群规模。由于Raft的Leader Election和Log Replication机制,etcd集群规模越大,消耗的时间越长,需要相应地增大Election/Heartbeat timeout。增大timeout会带来其它方面的问题,所以在光阴网络的生产环境中,etcd集群规模并不是很大,一般在40-50。其次是etcd集群的故障处理。由于数据的强一致性要求,数据与节点IP是绑定的。出现故障时,backup和restore都收到IP的限制,因此需要数量掌握add/remove节点操作,以便在故障时快速恢复。最后,对于集群性能调优,他给出了一些技巧。Etcd新增的metrics功能可以提供集群的健康状态,etcd-top工具可以查看网卡流量。
问题精选:
a. 我这里有一个web集群,有10个container,如果要扩展到100个,做负载均衡,能用etcd吗?
答:etcd只是作为存储,watch新节点或者容器并添加到集群中,业务方面还是需要自己去实现
b. 断网时,election是如何进行的?
答:通过election的timeout机制来实现。如果leader断网,follower节点timeout时,会成为Candidate,等待其他节点投票,得票最多的Candidate成为新Leader
c. 生产环境出现的网络抖动对etcd集群稳定性会有什么影响?如果有的话,怎么解决?
答:网络的抖动会导致频繁地Leader Election,会消耗大量的CPU,集群规模大时更为明显。对于跨区的集群,建议每个区使用独立的etcd,而非共享一个。
3. Kubernetes容器监控实践 — 杨乐(时速云)
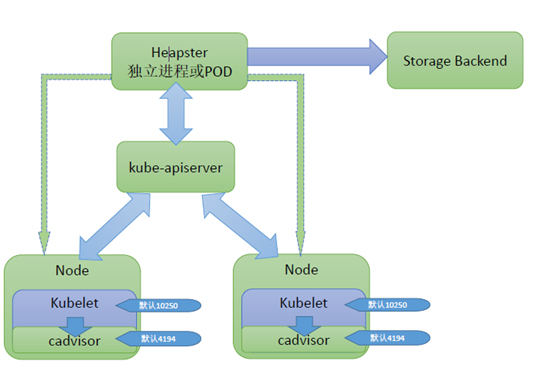
K8s的监控系统是通过外部插件实现的。Kubelet内置的cadvisor进行数据采集,influxdb负责数据存储,heapster负责数据管理(交互方式如图)。Cadvisor获取数据以后,kube-apiserver从各个slave节点的kubelet进程读取数据,返回给Heapster,Heapster将获取到的数据存储到influxdb中。监控信息存储在influxdb中,需要时直接从influxdb中读取即可。杨乐讲师对集群监控的每个组件逐一进行讲解,具体细节请查看ppt。
问答精选:
a. 容器的log如何处理?
答:K8s只能看到平台级的日志,不负责容器内应用的日志收集
b. 如何实现监控验证?
答:通过配置Kubelet的 Service Account 和Secret实现
c. Influxdb是否支持高可用?
答:目前influxdb支持集群
d. 上百G规模下,监控的实时性如何?
答:日志的采集、整理和存储完全是分开的,分别由不同的组件完成,所以不存在实时性的问题
e. 如果将容器日志也放到influxdb的话,有没有现成的处理方法?
答:Influxdb不能对日志进行优化。如果要处理日志的话,可以使用ElasticSearch等日志处理工具。
4. 触控Khaos平台经验分享 — 邓磊(触控科技)
Khaos平台是为了解决开发、测试和运维的痛点而生。基于Docker容器技术,一方面方便了运维测试新软件和进行脚本测试,另一方面开发人员只需要提交代码既可以快速测试,而不用关心部署、打包等问题。邓磊讲师针对Khaos平台的特性进行了分享。
通过这次沙龙,我们看到越来越多的技术人员开始使用和学习k8s,讨论的主题更为丰富,也更为深入。下次我们期待更多大牛分享他们对k8s技术的经验和理解,也欢迎您前来参与。
